
Ta-Da: A Paradigm Shift in AI Data Dynamics
Catalyzing AI Through Data Dynamics just as Ta-Da
Catalyzing AI Through Data Dynamics just as Ta-Da
Astrarizon research paper
Authors





Content Table


Abstract
The quest to understand and harness AI has been a journey stretching from ancient mythologies to the forefront of modern technology. This paper delves into the evolution of AI, tracing its roots from mythical origins like Hephaestus and Pandora, through philosophical and mathematical advancements, to the cutting-edge developments shaping today's digital world. We explore AI's impact across industries, emphasizing its transformative role in human-technology communication, and highlight the importance of quality data in AI development. Focusing on Ta-Da, we analyze its innovative approach to decentralized, blockchain-based data collection, offering a solution to the challenges of data diversity, quality, and cost. Ta-Da's model is not just a technical evolution; it's a paradigm shift in data collection, addressing ethical considerations and democratizing the data generation process.
Artificial Intelligence, or when man began to dream of playing God
1.a From an ancient mystical dream to the technology singularity
We find the first traces of artificial intelligences as early as protohistory, in myths and legends, where the idea of artificial beings with human intelligences began to appear.
Hephaestus, god of fire, craftsmanship and metalwork, would have created several of them, such as Talos, an intelligent bronze automaton whose role was to protect the island of Crete, or Pandora, an artificial woman he sculpted from clay and water.
It’s funny to think that many people regard AI as a “Pandora's Box”, whose contents would be the danger, probably without knowing that its name is inspired by the artificial being that opens it, releasing physical and emotional curses on Humanity.
Hermes Trismegistus (another mythical figure from Greek-Egyptian antiquity to whom the “Hermetica” are attributed, which actually are real writings probably produced in Alexandria) wrote about sacred mechanical statues believed to be capable of wisdom and emotion
"They have sensus and spiritus … by discovering the true nature of the gods, man has been able to reproduce it."
Alchemists would later claim him as the creator of their discipline. If the philosopher's stone and the transmutation of metals was their primary goal, the creation of artificial beings called “Homunculus” was another during the middle ages.
While for over two millennia it was thought that mysticism and the occult would enable the creation of artificial intelligence, in reality it is math, philosophy, and cognitive science that will convince us of the accessibility of its creation.
1.b From philosophical intuition to mathematical discovery.
While AI is of course based on programming, it also draws on centuries of research in cognitive science.
Tomas Hobbes wrote in his 1651 book “Leviathan” :
"…for reason is nothing but reckoning"
A definition of reasoning that evolved into the functionalist school of thought, which sees the mind as an information-processing system, comparing thought to calculation.
This movement rests on a major argument, the thesis of multiple realizability, which assumes that mental states can be explained without taking into account the material support in which they reside, and therefore asserts that thought could just as easily emerge from a machine.
If, of course, this way of thinking can show its limits, notably with the Chinese room thought experiment, it will lead to other movements such as connectionism, which today serves as the basis for all research into neural networks.
As far as math is concerned, it is difficult to summarize several centuries of notable discoveries, as the field is so vast. From Leibniz’s chain rule, are fundamental today to train neural networks by backpropagation, to the work of Thomas Bayes in probability, notably on what is commonly known as the Bayes’ formula of knowledge, leading today to research on a predictive vision of the human brain, where the latter encodes beliefs inferred from its experiences and stimuli, in order to generate predictions, presupposedly necessary for the emergence of consciousness.
But from a purely programming point of view, on the other hand, the true conceptualization of artificial intelligence comes directly from the works of Alan Turing and his famous Turing test, supposed to be used as a delimitation to consider a machine as thinking.
1.c 70 years of AI in a nutshell
The first wording of this field of research as Artificial Intelligence emerged in 1956, at the Dartmouth College Conference organized by IBM researchers. The next two decades would see the first AI boom, notably with the appearance of the first chess-playing programs, semantic net translators, and machine learning algorithms. But AI’s statistical approach, particularly in linguistic fields, quickly shows its limits, as it lacks two crucial elements: a lot of data and computational power.
At the time, scientists were already (over)enthusiastic about the field like Marvin Minsky who, in 1970, asserted that a machine with a general intelligence similar to an average human would be conceivable within 3 to 8 years. But this optimism was soon to fade with the first difficulties encountered in what became known as the first AI winter in the 70s, a period when research and funding were severely curtailed.
The arrival of a new approach, this time logical with the arrival of the first expert systems such as Lisp Machines for industrial and commercial purposes, led to a revival of interest in the 80s. But this was short-lived as the great promises of this field were deemed unrealistic, leading to a second slowdown of the domain in the end of the 80s.
It wasn’t until the middle of the 90s that AI began to seduce again with major new scientific discoveries and practical achievement, notably with Deep Blue’s victory over the world chess champion in 1997, Garry Kasparov, considered to be the apotheosis of purely logical AI.
But this wasn’t the only reason for this new hype, as the Internet began to be massively adopted, it was also the time for a return to a more statistical approaches as the data we’d been missing, this new oil for growth, was now within reach and that our computational capacity was now infinitely more developed.
We’re now in the third AI boom, the era of Big Data. This new era has seen the arrival of mass-market voice recognition tools like Siri, pushing the man vs. machine battle even further. Notably with Watson’s victory in the TV game Jeopardy in 2011, and Alpha Go’s victory in the strategic game of Go in 2016, which was still one of the only logic games in which humans could outperform the machine. But the appeal and real use cases for users were still in their infancy.
Since the invention of Transformers, a new type of AI architecture in 2017, the acceleration phase of this field has begun and reached its full boom with the release of Chat GPT and MidJourney in late 2022 and early 2023, making the whole world realize that the era in which we live is about to undergo a major transformation.
We find the first traces of artificial intelligences as early as protohistory, in myths and legends, where the idea of artificial beings with human intelligences began to appear.
Hephaestus, god of fire, craftsmanship and metalwork, would have created several of them, such as Talos, an intelligent bronze automaton whose role was to protect the island of Crete, or Pandora, an artificial woman he sculpted from clay and water.
It’s funny to think that many people regard AI as a “Pandora's Box”, whose contents would be the danger, probably without knowing that its name is inspired by the artificial being that opens it, releasing physical and emotional curses on Humanity.
Hermes Trismegistus (another mythical figure from Greek-Egyptian antiquity to whom the “Hermetica” are attributed, which actually are real writings probably produced in Alexandria) wrote about sacred mechanical statues believed to be capable of wisdom and emotion
"They have sensus and spiritus … by discovering the true nature of the gods, man has been able to reproduce it."
Alchemists would later claim him as the creator of their discipline. If the philosopher's stone and the transmutation of metals was their primary goal, the creation of artificial beings called “Homunculus” was another during the middle ages.
While for over two millennia it was thought that mysticism and the occult would enable the creation of artificial intelligence, in reality it is math, philosophy, and cognitive science that will convince us of the accessibility of its creation.
1.b From philosophical intuition to mathematical discovery.
While AI is of course based on programming, it also draws on centuries of research in cognitive science.
Tomas Hobbes wrote in his 1651 book “Leviathan” :
"…for reason is nothing but reckoning"
A definition of reasoning that evolved into the functionalist school of thought, which sees the mind as an information-processing system, comparing thought to calculation.
This movement rests on a major argument, the thesis of multiple realizability, which assumes that mental states can be explained without taking into account the material support in which they reside, and therefore asserts that thought could just as easily emerge from a machine.
If, of course, this way of thinking can show its limits, notably with the Chinese room thought experiment, it will lead to other movements such as connectionism, which today serves as the basis for all research into neural networks.
As far as math is concerned, it is difficult to summarize several centuries of notable discoveries, as the field is so vast. From Leibniz’s chain rule, are fundamental today to train neural networks by backpropagation, to the work of Thomas Bayes in probability, notably on what is commonly known as the Bayes’ formula of knowledge, leading today to research on a predictive vision of the human brain, where the latter encodes beliefs inferred from its experiences and stimuli, in order to generate predictions, presupposedly necessary for the emergence of consciousness.
But from a purely programming point of view, on the other hand, the true conceptualization of artificial intelligence comes directly from the works of Alan Turing and his famous Turing test, supposed to be used as a delimitation to consider a machine as thinking.
1.c 70 years of AI in a nutshell
The first wording of this field of research as Artificial Intelligence emerged in 1956, at the Dartmouth College Conference organized by IBM researchers. The next two decades would see the first AI boom, notably with the appearance of the first chess-playing programs, semantic net translators, and machine learning algorithms. But AI’s statistical approach, particularly in linguistic fields, quickly shows its limits, as it lacks two crucial elements: a lot of data and computational power.
At the time, scientists were already (over)enthusiastic about the field like Marvin Minsky who, in 1970, asserted that a machine with a general intelligence similar to an average human would be conceivable within 3 to 8 years. But this optimism was soon to fade with the first difficulties encountered in what became known as the first AI winter in the 70s, a period when research and funding were severely curtailed.
The arrival of a new approach, this time logical with the arrival of the first expert systems such as Lisp Machines for industrial and commercial purposes, led to a revival of interest in the 80s. But this was short-lived as the great promises of this field were deemed unrealistic, leading to a second slowdown of the domain in the end of the 80s.
It wasn’t until the middle of the 90s that AI began to seduce again with major new scientific discoveries and practical achievement, notably with Deep Blue’s victory over the world chess champion in 1997, Garry Kasparov, considered to be the apotheosis of purely logical AI.
But this wasn’t the only reason for this new hype, as the Internet began to be massively adopted, it was also the time for a return to a more statistical approaches as the data we’d been missing, this new oil for growth, was now within reach and that our computational capacity was now infinitely more developed.
We’re now in the third AI boom, the era of Big Data. This new era has seen the arrival of mass-market voice recognition tools like Siri, pushing the man vs. machine battle even further. Notably with Watson’s victory in the TV game Jeopardy in 2011, and Alpha Go’s victory in the strategic game of Go in 2016, which was still one of the only logic games in which humans could outperform the machine. But the appeal and real use cases for users were still in their infancy.
Since the invention of Transformers, a new type of AI architecture in 2017, the acceleration phase of this field has begun and reached its full boom with the release of Chat GPT and MidJourney in late 2022 and early 2023, making the whole world realize that the era in which we live is about to undergo a major transformation.
AI Industry Landscape
Although the term can be hackneyed and sometimes misused, the AI market affects virtually every sector of activity, from education, finance, logistics, healthcare, for very specific applications like the discovery of new materials or drugs and even in deeptech research like nuclear fusion. Here we'll focus more on the part dealing with communication between humans and technology, through speech and text recognition, but also the emerging market for generative AIs and how they are trained.
1.a The AI market today.
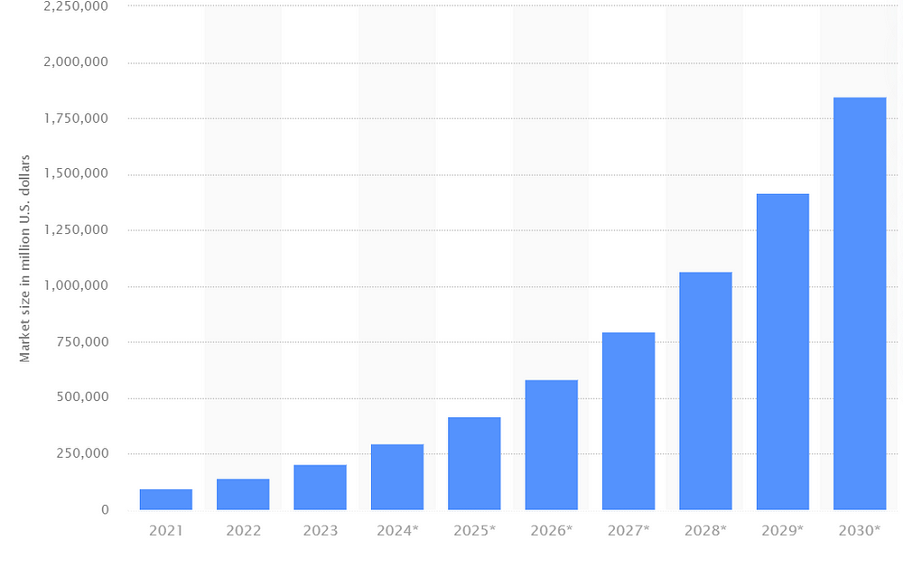
For a few years now, AI in linguistics is maturing and entering a go-to-market phase. If their use was still reserved for companies to offer a new way of using a product, AI is starting to fall into the hands of users benefiting from an acceleration of innovation, becoming the product itself. Large Language Models have entered mass adoption and are becoming increasingly generalized thanks to the use of multi-modal agents and generative AI such as stable diffusion. According to studies, the total AI market is expected to grow from 200 billion today, to around 2000 billion by 2030, a 10-fold increase in less than a decade.
While voice assistants like Siri and connected speakers like Alexa are long-standing innovations, they have unfortunately remained more at the gadget stage due to their limited capacity for action. In addition, almost only large technology companies such as GAFAM were able to offer high-performance voice recognition, as they had the necessary resources and user-base to train their AIs. All the other companies that have tried, such as car manufacturers for GPS voice-command, or voice chat-bots for telephone assistance, have often been almost unusable in practice during the previous decade.
But this could be about to change, not least with new types of AI like Large Action Model, and hardware and software layers built specifically for non-app-based interactions like the recent Rabbit R1 or Hu.ma.ne’s AI-pin. We're seeing a certain trend towards changing the way we interact with technology in a more profound way, while at the same time allowing us to abstract ourselves from screens whose addictions are becoming increasingly problematic from a societal point of view.
Therefore, the voice recognition market is likely to take a new turn and could become much more present in our daily lives, such as in the home automation sector, but also in AI assistants, which are becoming more and more popular as companions. Also, efforts in terms of language support have always been much greater for English than for other major languages, and mass adoption will require catching up to better cover people’s diversity, particularly in high-population emerging countries.
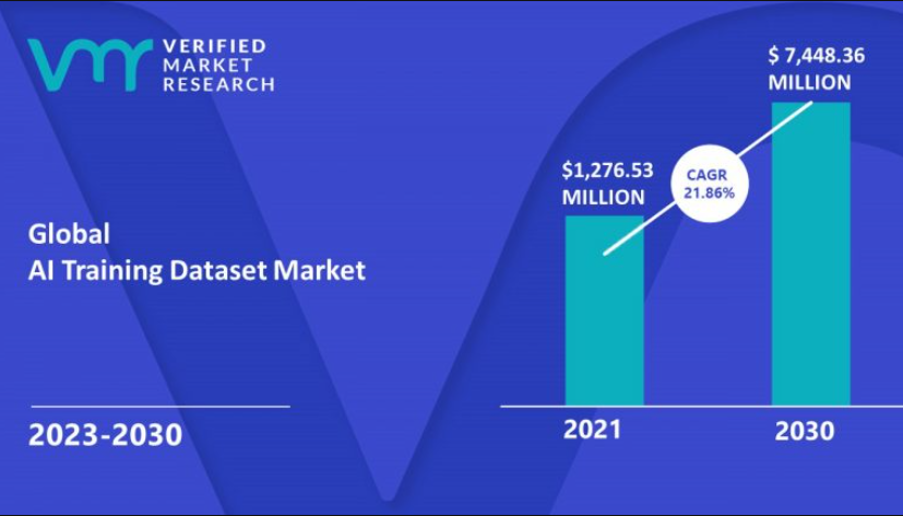
The data collection and labeling market for text, image and voice recognition is also expected to grow significantly, from around 1.2 billion in 2021 to over 7 billion by 2030 according to Verified Market Research, but other analyses see this market climbing to over 17 billion by the end of the decade.
It’s interesting to note that today’s key companies in this market such as Amazon Mechanical Turk, Playment, Scale AI, Labelbox, specialize more in automatic or human data annotation on existent data collection rather than in data production.
Most of the data used in AI training today is not specifically created for it, for example LLMs uses data sourced almost exclusively from the Internet, which can reduce their efficiency, data quality and be highly biased if not properly selected and cleaned. That’s why a lot of established companies are more specialized in data sorting, anomaly detection and making this data readable for algorithms with labeling. Therefore, there could be a growing interest in the large-scale production of data with high quality for more specific training and to cover the blind spots in existing datasets.
2.b Micro-tasking and trustless collaborative data production and annotation.
The microtasking market is particularly used in the AI data annotation market, but also in anything to do with moderating social networks, or any kind of “botting” on the Internet. With its aim of horizontally dividing work by parceling out unskilled tasks, it is often seen as neo-Taylorism adapted to the digital age and its needs. In 2019, the micro-tasking market was worth 1.4 billion and forecasts predicted very significant growth by 2025.
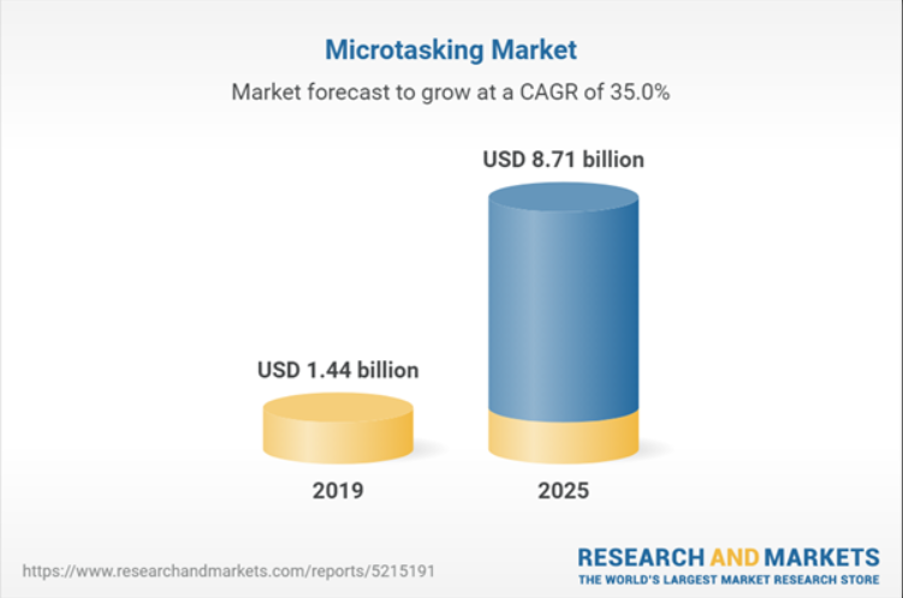
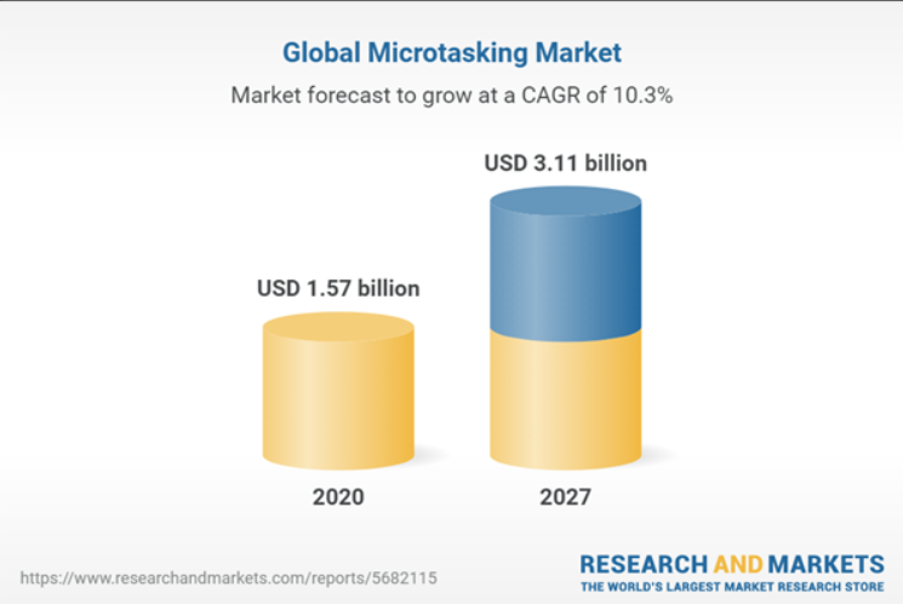
However, more recent forecasts are less enthusiastic, reducing the latter to only 3 billion by 2027. The main reason lies in the fact that the market has encountered several difficulties with micro-tasking, notably in terms of quality, but also in terms of confidence by the services offered by this type of company.
Without a game-theoretic mechanism, it’s difficult for micro-tasking companies to ensure that the work their micro-workers do is honestly made, and to prove to their customer that potential quality checks are carried out properly.
This is why blockchain can be a major asset for creating large collaborative networks, offering transparency as much as traceability of workers’ tasks and checkers’ proof, while enabling economic mechanisms to ensure that all participants are honest. Blockchain can also be important for improving the ethics of this type of work, ensuring good remuneration for workers without intermediaries.

Data continues to be a significant barrier
Securing data for AI training is a complex and costly process, vital for algorithm accuracy. High-grade data is crucial, yet sourcing it proves tough. AI systems need diversity in data to be effective, yet capturing it is a challenge. Custom datasets, essential for specific AI needs, come at a hefty price. This leads to a hefty financial toll, with data acquisition often consuming nearly 60% of an AI project's budget. Overcoming these barriers is critical for AI progress, demanding innovative solutions for economical, varied, and top-tier data collection.
Ta-Da aims to meet the growing demand for qualified data by becoming the first decentralized platform on the blockchain for data collection. Its inception is more than just an addition to existing data collection methods; it represents a new approach. It aims to provide cost-effective, high-quality data collection, emphasizing flexibility and transparency via blockchain technology. This strategy not only ensures fair compensation for data contributors but also guarantees thorough traceability in data handling
1.a The AI market today.
For a few years now, AI in linguistics is maturing and entering a go-to-market phase. If their use was still reserved for companies to offer a new way of using a product, AI is starting to fall into the hands of users benefiting from an acceleration of innovation, becoming the product itself. Large Language Models have entered mass adoption and are becoming increasingly generalized thanks to the use of multi-modal agents and generative AI such as stable diffusion. According to studies, the total AI market is expected to grow from 200 billion today, to around 2000 billion by 2030, a 10-fold increase in less than a decade.
While voice assistants like Siri and connected speakers like Alexa are long-standing innovations, they have unfortunately remained more at the gadget stage due to their limited capacity for action. In addition, almost only large technology companies such as GAFAM were able to offer high-performance voice recognition, as they had the necessary resources and user-base to train their AIs. All the other companies that have tried, such as car manufacturers for GPS voice-command, or voice chat-bots for telephone assistance, have often been almost unusable in practice during the previous decade.
But this could be about to change, not least with new types of AI like Large Action Model, and hardware and software layers built specifically for non-app-based interactions like the recent Rabbit R1 or Hu.ma.ne’s AI-pin. We're seeing a certain trend towards changing the way we interact with technology in a more profound way, while at the same time allowing us to abstract ourselves from screens whose addictions are becoming increasingly problematic from a societal point of view.
Therefore, the voice recognition market is likely to take a new turn and could become much more present in our daily lives, such as in the home automation sector, but also in AI assistants, which are becoming more and more popular as companions. Also, efforts in terms of language support have always been much greater for English than for other major languages, and mass adoption will require catching up to better cover people’s diversity, particularly in high-population emerging countries.
The data collection and labeling market for text, image and voice recognition is also expected to grow significantly, from around 1.2 billion in 2021 to over 7 billion by 2030 according to Verified Market Research, but other analyses see this market climbing to over 17 billion by the end of the decade.
It’s interesting to note that today’s key companies in this market such as Amazon Mechanical Turk, Playment, Scale AI, Labelbox, specialize more in automatic or human data annotation on existent data collection rather than in data production.
Most of the data used in AI training today is not specifically created for it, for example LLMs uses data sourced almost exclusively from the Internet, which can reduce their efficiency, data quality and be highly biased if not properly selected and cleaned. That’s why a lot of established companies are more specialized in data sorting, anomaly detection and making this data readable for algorithms with labeling. Therefore, there could be a growing interest in the large-scale production of data with high quality for more specific training and to cover the blind spots in existing datasets.
2.b Micro-tasking and trustless collaborative data production and annotation.
The microtasking market is particularly used in the AI data annotation market, but also in anything to do with moderating social networks, or any kind of “botting” on the Internet. With its aim of horizontally dividing work by parceling out unskilled tasks, it is often seen as neo-Taylorism adapted to the digital age and its needs. In 2019, the micro-tasking market was worth 1.4 billion and forecasts predicted very significant growth by 2025.
However, more recent forecasts are less enthusiastic, reducing the latter to only 3 billion by 2027. The main reason lies in the fact that the market has encountered several difficulties with micro-tasking, notably in terms of quality, but also in terms of confidence by the services offered by this type of company.
Without a game-theoretic mechanism, it’s difficult for micro-tasking companies to ensure that the work their micro-workers do is honestly made, and to prove to their customer that potential quality checks are carried out properly.
This is why blockchain can be a major asset for creating large collaborative networks, offering transparency as much as traceability of workers’ tasks and checkers’ proof, while enabling economic mechanisms to ensure that all participants are honest. Blockchain can also be important for improving the ethics of this type of work, ensuring good remuneration for workers without intermediaries.
Ta-Da's Role in Advancing AI Data Utilization
The advancement of AI hinges on several critical factors: access to extensive datasets, cutting-edge algorithms, enhanced computing power, and substantial AI research investment. These elements collectively propel AI forward, influencing everything from everyday technology to complex industrial systems. Central to these advancements is the need for high-quality, extensive data.
Data continues to be a significant barrier
Securing data for AI training is a complex and costly process, vital for algorithm accuracy. High-grade data is crucial, yet sourcing it proves tough. AI systems need diversity in data to be effective, yet capturing it is a challenge. Custom datasets, essential for specific AI needs, come at a hefty price. This leads to a hefty financial toll, with data acquisition often consuming nearly 60% of an AI project's budget. Overcoming these barriers is critical for AI progress, demanding innovative solutions for economical, varied, and top-tier data collection.
Ta-Da aims to meet the growing demand for qualified data by becoming the first decentralized platform on the blockchain for data collection. Its inception is more than just an addition to existing data collection methods; it represents a new approach. It aims to provide cost-effective, high-quality data collection, emphasizing flexibility and transparency via blockchain technology. This strategy not only ensures fair compensation for data contributors but also guarantees thorough traceability in data handling
Ta-Da’s operational model and their quests
How it operates:
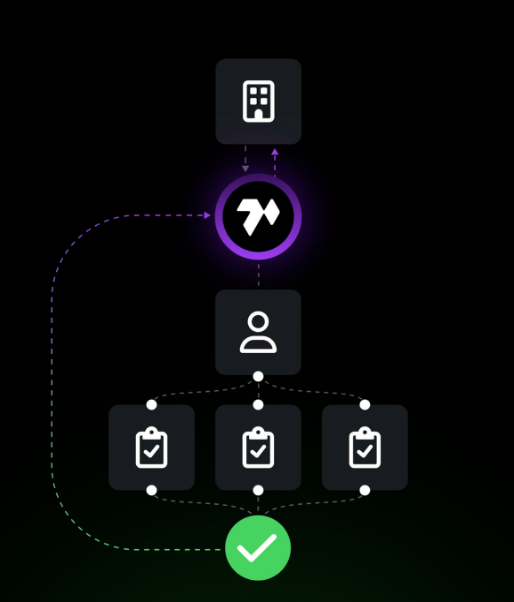
Task Initiation: An AI&ML Company submits a job on Ta-Da
Task Breakdown: The platform splits the job into microtasks that are sent to the producers
Execution: Once the producers has produced the data, it is sent to the checker
Quality Assurance: The checkers verify the produced data and vote for its validity
Rewarding Successful Completion: Upon successful validation of the tasks, users who contributed are compensated accordingly.
Quality Assurance
Quality assurance in data collection is essential to ensure that the data meets the specific needs of the company using it. Quality data must align with the company's set criteria and receive approval from a trusted subset of the community. For instance, if multiple checkers independently agree that an audio recording contains background noise, and such noise aligns with the company’s requirements, the data is deemed valid. Conversely, if the company did not desire background noise, the data is invalid.
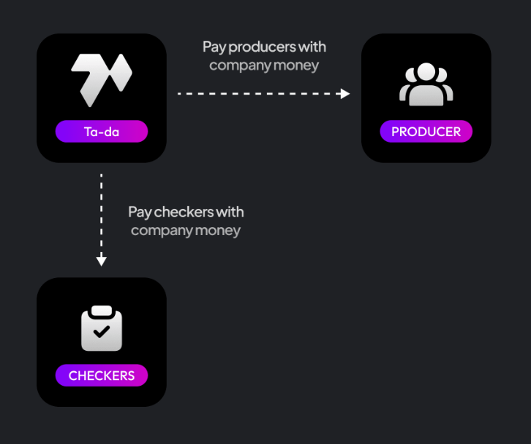
To encourage the production of quality data, Ta-Da implements a deposit system where users lock in a small amount of tokens for every action, whether producing or validating data. This deposit serves as a motivational tool, ensuring users are diligent in their tasks. If a producer’s data is validated, they are rewarded with tokens. If not, they forfeit their deposit and gain nothing. Similarly, checkers are incentivized through a consensus mechanism. Those who vote in the minority may lose their stake, ensuring that they perform their validation duties conscientiously.
Data is Valid
Data is Invalid
This system is not just about rewarding accuracy; it also minimizes costs for companies. When checkers invalidate data, they are compensated from the producer’s deposit, ensuring that companies do not incur costs for data that fails to meet their criteria. This quality assurance process, deeply rooted in DeFi and blockchain protocols, proves effective in maintaining high standards in data collection and validation on Ta-Da.
A Response to Data Collection Challenges
Ta-Da emerges as a solution aimed at improving the data collection process. Originating from Vivoka's experience in speech recognition, it was conceptualized to overcome the complezities of traditional data collection methods. The platform combines blockchain technology's security and transparency with a user-focused approach to data provision, aligning with specific client needs.
The vision goes beyond conventional data collection. It aims to set new industry standards, enabling AI companies to tailor data requirements and engage communities effectively.
Operational Strategy
Blockchain Integration: Utilizing blockchain for secure, transparent data collection.
Platform Flexibility: Adapting to the evolving data needs of AI development.
Quality Assurance: Ensuring the accuracy and relevance of the data collected.
Community Engagement: Facilitating active participation from data creators and consumers.
Exploring Blockchain's Edge in Data Collection
Why turn to blockchain for data collection? It's a matter of upgrading to a system where transparency, security, and fairness aren't just nice-to-haves, but foundational pillars. Blockchain's ledger technology is tamper-proof, ensuring that every piece of data is accurately recorded and verifiable by anyone, at any time. It's a leap towards operations that are not just efficient, but also inherently trustworthy.

Decentralization: By removing centralized control and unwanted intermediaries, blockchain technology democratizes the data collection process. Companies save on costs, and community members are fairly compensated, creating a win-win scenario for all involved.

Fair Remuneration: Companies save on costs, and community members are fairly compensated, creating a win-win scenario for all involved.
Transparency in Community Engagement: The blockchain enables a transparent and auditable process. Community members can verify transaction legitimacy, understand the reasons behind data validation or slashing, and ensure fairness in the process.

Immutable Record Keeping: Blockchain's distributed ledger technology ensures every transaction is permanently recorded and unalterable. This guarantees the authenticity of the data collected, making fraud and data manipulation virtually impossible.
Competition

The competitive landscape for Ta-Da is represented by a mix of full outsourcing and microtasking companies, each bringing their own strengths to the field of data collection. However, Ta-Da distinguishes itself by excelling in key areas. It stands out with its superior data quality and robust data validation processes, earning a full five-star rating in each category. Unlike many of its competitors, Ta-Da is a decentralized platform, which not only ensures a wide diversity of data but also contributes to a competitive pricing structure. This decentralization is a unique attribute that sets Ta-Da apart from other full outsourcing services like Appen and Defined. AI, as well as microtasking platforms such as Clickworker, where centralization remains a core operational feature. In terms of price, Ta-Da offers a more affordable solution without compromising on the quality of data, outperforming giants like Amazon and service marketplaces like Fiverr. This competitive edge is crucial for Ta-Da as it aims to redefine the paradigm of data collection for AI applications.
As the AI vertical evolves, Ta-Da is strategically positioned to support this growth with diversified, quality data, ensuring AI technologies reach their optimum potential, redefining data collection and establishing a new paradigm in the interaction between data creation and consumption.
Ta-Da's Strategy: Data Collection and Gamification
Central to Ta-Da's success is the community it cultivates. This product thrives on engaging users in micro-tasks, rewarding them for their contributions.
Upon initial interaction with the Ta-Da app, users encounter a gamified environment. Task cards appear, prompting users to swipe through and select one. Each task, such as an 'Image Classification' assignment, involves a playful interaction like tagging images—reminiscent of playing trivia games.
Users are motivated through a clear system:
The Energy system stands as a pillar of the user experience on Ta-Da. It limits the number of tasks a user can complete within a certain timeframe, regenerating over a period of 5-8 hours. This feature alone lends the platform a gamified quality. However, this is just the start.
Ta-Da introduces another gamification element with 'Tadz,' a robot Avatar that acts as a user's virtual representation. This avatar not only tracks the user's progress but can also be personalized with a variety of items, enhancing both aesthetics and functionality. A few item examples:
Leagues & Leaderboards
Ta-Da's gamified experience is further enhanced through the introduction of leagues and leaderboards. Users progress through four leagues, each divided into three stages. The progression is competitive:
Participants start in Bronze 1, competing within their league. Weekly assessments promote the top 20% to the next league, demote the bottom 20%, while the rest remain.
Some league promotions depend on other mechanics. For example, moving from Silver 3 to Gold 1 might require a certain account level.
This structure motivates users to actively complete tasks for advancement and better rewards. Moreover, league standings are visible in user profiles, adding a social dimension.
Leaderboards complement this by displaying global user rankings.
Level & Skill
The final component of Ta-Da's gamified experience is the Account Level and Skill Points system.
Users earn XP Points for each completed task, along with other types of rewards. These XP Points contribute to the growth of their account, enabling them to gain Skill Points upon reaching new levels.
Skill Points unlock various skills, enhancing the user's capabilities and interaction within the platform:
Thus, Ta-Da is striving to offer a complete gamified experience through Energy, Avatar, Leagues, Leaderboard, Levels, Skill & XP
In conclusion, Ta-Da presents a sustainable model, blending motivation, competition, and reward in a cohesive ecosystem. Challenges might include ensuring continued user engagement, balancing competitive elements to cater to diverse user skill levels, and maintaining a fair and transparent reward system.
The platform's success in maintaining user interest and its adaptability to evolving user needs will be key indicators of its long-term effectiveness and impact in the world of gamified experiences.
Upon initial interaction with the Ta-Da app, users encounter a gamified environment. Task cards appear, prompting users to swipe through and select one. Each task, such as an 'Image Classification' assignment, involves a playful interaction like tagging images—reminiscent of playing trivia games.
Users are motivated through a clear system:
- Purpose: Users are motivated to complete tasks.
- Energy Usage: Participation requires using Energy.
- Token Lock-In: Temporarily locking in Ta-Da tokens is necessary for starting a task.
- Rewards: Successful completion of tasks leads to rewards.
- Risks: Incorrect submissions result in the loss of locked tokens.
The Energy system stands as a pillar of the user experience on Ta-Da. It limits the number of tasks a user can complete within a certain timeframe, regenerating over a period of 5-8 hours. This feature alone lends the platform a gamified quality. However, this is just the start.
Ta-Da introduces another gamification element with 'Tadz,' a robot Avatar that acts as a user's virtual representation. This avatar not only tracks the user's progress but can also be personalized with a variety of items, enhancing both aesthetics and functionality. A few item examples:
- Battery: Recharges Energy. (Utility)
- Battery Slot: Expands maximum Energy level. (Utility)
- Emotes: Offers animated eyes with a rarity system. (Cosmetic)
- Ears: Provides different styles of ears for the Avatar. (Cosmetic)
Leagues & Leaderboards
Ta-Da's gamified experience is further enhanced through the introduction of leagues and leaderboards. Users progress through four leagues, each divided into three stages. The progression is competitive:
- Bronze: Stages 1, 2, 3
- Silver: Stages 1, 2, 3
- Gold: Stages 1, 2, 3
- Diamond: Stages 1, 2, 3
Participants start in Bronze 1, competing within their league. Weekly assessments promote the top 20% to the next league, demote the bottom 20%, while the rest remain.
Some league promotions depend on other mechanics. For example, moving from Silver 3 to Gold 1 might require a certain account level.
This structure motivates users to actively complete tasks for advancement and better rewards. Moreover, league standings are visible in user profiles, adding a social dimension.
Leaderboards complement this by displaying global user rankings.
Level & Skill
The final component of Ta-Da's gamified experience is the Account Level and Skill Points system.
Users earn XP Points for each completed task, along with other types of rewards. These XP Points contribute to the growth of their account, enabling them to gain Skill Points upon reaching new levels.
Skill Points unlock various skills, enhancing the user's capabilities and interaction within the platform:
- Endurance: Increases the user's maximum energy level. For example, all users start with a 100-point energy bar. By allocating a skill point to this attribute, the user could have a 120-point energy bar.
- Speed: Reduces Energy regeneration time.
- Agility: Allows the user to gain multiple skill points when leveling up.
- Luck: Enhances the user's chance of looting items and gifts when performing tasks.
Thus, Ta-Da is striving to offer a complete gamified experience through Energy, Avatar, Leagues, Leaderboard, Levels, Skill & XP
In conclusion, Ta-Da presents a sustainable model, blending motivation, competition, and reward in a cohesive ecosystem. Challenges might include ensuring continued user engagement, balancing competitive elements to cater to diverse user skill levels, and maintaining a fair and transparent reward system.
The platform's success in maintaining user interest and its adaptability to evolving user needs will be key indicators of its long-term effectiveness and impact in the world of gamified experiences.
AI Data Utilization and Ta-Da’s long-term vision
The better the data, the better the model
We are increasingly entering the era of artificial intelligence, which will gradually enter our lives and open up new worlds, new possibilities and opportunities.
On the road to this ambitious future, companies intent on creating artificial intelligence capable of changing the world will find an obstacle in front of them: the need for data.
Not only will a large amount of data be needed, but this will have to be of quality. The challenges facing the AI sector are many, but among the most difficult ones will be how to find data that is both cheap and good quality.
The better the data, the better the model they say; meaning that a good model cannot be based on inaccurate or unreliable data. So companies are prepared to pay for this data, and they need someone to provide it and be able to prove its reliability.
This is where Ta-Da excels, with a DePin mechanism that allows them to collect data, validate and sell it.
The need for data
Companies will increasingly rely on AI for its enormous potential in increasing business productivity or for new business models created by it. And they will need more and more data to create quality models.
Growth of almost $1 trillion is expected until 2030 in the artificial intelligence market.
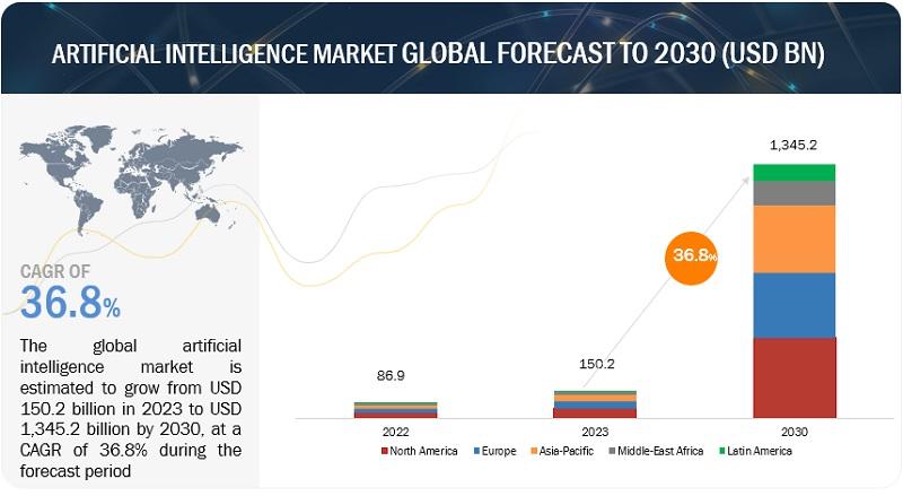
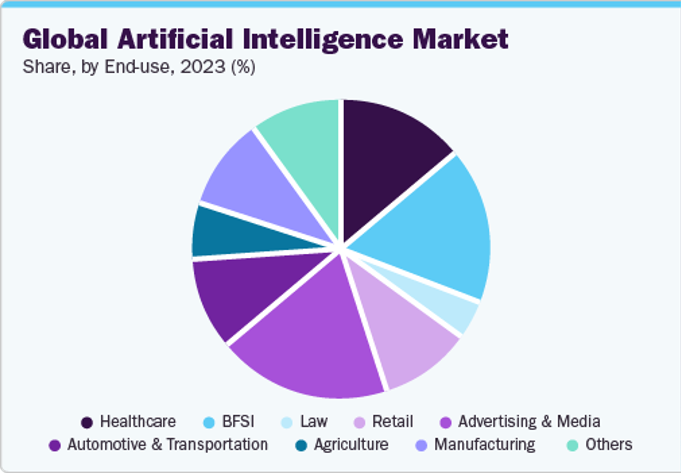
Demand comes from a multitude of sectors, demonstrating the revolutionary scope and versatility of this technology, which by 2023 had already a market of more than $150 billion in a variety of sectors, from hospitals to manufacturing.
Ta-Da is positioned above these sectors, as a service capable of procuring data for companies of all kinds. Users will take part in the creation of this data and receive part of the earnings through an efficient remuneration system enabled by blockchain technology.
Companies will require data and search for ways to acquire or create them. Ta-Da data promises to be cheap, qualitative and highly specialised, being extremely attractive for a ton of different use cases.
Datasets are key and long term vision
Datasets are the basic ingredients of any AI project. They have algorithms and give them data to learn and make predictions. Without good datasets, ai models results would not be accurate or useful.
There are good free datasets, but there’s an increasing massive need for more data. Data is the new oil that will sustain the upcoming AI revolution and a paradigm shift in the programming sector.
Artificial intelligence doesn’t require a big number of rules, but mostly a big amount of data, the more the better, and there will be a fight to get the most qualitative data. And to create new ones, with the more or specific data needed based on the complexity or specificity of the problem that needs to be solved.
How much data is needed and what market will it have?
To give some context for famous AI models:
Lot of data can be found on the internet or taken from free datasets, but the quantity of the data needs to be matched with a sufficient quality to have good results: when Microsoft tried to train his model using twitter content, it ended up giving racist results. Other than that famous AI models are trained on mountains of data, but that’s for general purposes AI models which are only a part of the possible ai models the world will need. Companies will also need diverse sets of data for specific ai models, and so will prefer less amount of data but highly specialized. Those are difficult to obtain and extremely expensive; this will be the big growing niche in which Ta-Da will place itself.
GROWTH PERSPECTIVES
Ta-Da's DePin model will facilitate the generation of data that will be of high quality, specialized, provably verified and economically competitive for different specific tasks. These factors together will make Ta-Da's extremely competitive and its future potential rosy. This will rely on their ability to create both a large enough and diverse number of users generating data and find companies commissioning datasets creation. To give some context on the potential growth and demand for this service, the market size value for AI datasets was 1.62 billions in 2022 and expected to grow to 13.65 billions by 2032. As has already been demonstrated for other projects in the crypto world, democratising the creation of infrastructure with DePin makes it possible to cut costs, increase quality and speed up processes; Ta-Da will use DePin to create data that will be extremely competitive within the datasets market. In the wake of other DePin projects, we could expect rapid growth resulting from the competitiveness possible through blockchain technology and democratisation of data creation processes. “The strength of decentralization and crypto technology can be the key to unlocking the doors of progress and innovation.”
We are increasingly entering the era of artificial intelligence, which will gradually enter our lives and open up new worlds, new possibilities and opportunities.
On the road to this ambitious future, companies intent on creating artificial intelligence capable of changing the world will find an obstacle in front of them: the need for data.
Not only will a large amount of data be needed, but this will have to be of quality. The challenges facing the AI sector are many, but among the most difficult ones will be how to find data that is both cheap and good quality.
The better the data, the better the model they say; meaning that a good model cannot be based on inaccurate or unreliable data. So companies are prepared to pay for this data, and they need someone to provide it and be able to prove its reliability.
This is where Ta-Da excels, with a DePin mechanism that allows them to collect data, validate and sell it.
The need for data
Companies will increasingly rely on AI for its enormous potential in increasing business productivity or for new business models created by it. And they will need more and more data to create quality models.
Growth of almost $1 trillion is expected until 2030 in the artificial intelligence market.
Demand comes from a multitude of sectors, demonstrating the revolutionary scope and versatility of this technology, which by 2023 had already a market of more than $150 billion in a variety of sectors, from hospitals to manufacturing.
Ta-Da is positioned above these sectors, as a service capable of procuring data for companies of all kinds. Users will take part in the creation of this data and receive part of the earnings through an efficient remuneration system enabled by blockchain technology.
Companies will require data and search for ways to acquire or create them. Ta-Da data promises to be cheap, qualitative and highly specialised, being extremely attractive for a ton of different use cases.
Datasets are key and long term vision
Datasets are the basic ingredients of any AI project. They have algorithms and give them data to learn and make predictions. Without good datasets, ai models results would not be accurate or useful.
There are good free datasets, but there’s an increasing massive need for more data. Data is the new oil that will sustain the upcoming AI revolution and a paradigm shift in the programming sector.
Artificial intelligence doesn’t require a big number of rules, but mostly a big amount of data, the more the better, and there will be a fight to get the most qualitative data. And to create new ones, with the more or specific data needed based on the complexity or specificity of the problem that needs to be solved.
How much data is needed and what market will it have?
To give some context for famous AI models:
- GPT was trained on 570 gigabytes of text data, or about 300 billion words
- Stable diffusion (DALL-E, Midjourney) was trained on the a dataset with 5.8 billion image-text pairs.
Lot of data can be found on the internet or taken from free datasets, but the quantity of the data needs to be matched with a sufficient quality to have good results: when Microsoft tried to train his model using twitter content, it ended up giving racist results. Other than that famous AI models are trained on mountains of data, but that’s for general purposes AI models which are only a part of the possible ai models the world will need. Companies will also need diverse sets of data for specific ai models, and so will prefer less amount of data but highly specialized. Those are difficult to obtain and extremely expensive; this will be the big growing niche in which Ta-Da will place itself.
GROWTH PERSPECTIVES
Ta-Da's DePin model will facilitate the generation of data that will be of high quality, specialized, provably verified and economically competitive for different specific tasks. These factors together will make Ta-Da's extremely competitive and its future potential rosy. This will rely on their ability to create both a large enough and diverse number of users generating data and find companies commissioning datasets creation. To give some context on the potential growth and demand for this service, the market size value for AI datasets was 1.62 billions in 2022 and expected to grow to 13.65 billions by 2032. As has already been demonstrated for other projects in the crypto world, democratising the creation of infrastructure with DePin makes it possible to cut costs, increase quality and speed up processes; Ta-Da will use DePin to create data that will be extremely competitive within the datasets market. In the wake of other DePin projects, we could expect rapid growth resulting from the competitiveness possible through blockchain technology and democratisation of data creation processes. “The strength of decentralization and crypto technology can be the key to unlocking the doors of progress and innovation.”
Conclusion
In conclusion, the journey of AI from mystical concept to technological reality reflects humanity's enduring quest for knowledge and progress. The current landscape of AI is marked by rapid advancements, increasingly integrating into various sectors and reshaping our interaction with technology. Ta-Da emerges as a crucial player in this landscape, offering a blockchain-based platform that redefines data collection for AI. By ensuring data diversity, quality, and affordability, Ta-Da addresses the critical challenges facing AI development today. Its commitment to ethical practices and community engagement sets a new standard in the industry. As we look to the future, the continued evolution of AI and platforms like Ta-Da will undoubtedly lead to more innovative solutions, driving progress and opening new possibilities in the digital world. The potential of AI, fueled by the right tools and ethical considerations, holds the promise of a future where technology and human intellect coalesce to create unprecedented opportunities and solutions.